

Oto, co musisz wiedzieć:
-
Sześć głównych modeli AI otrzymuje po 10 000 USD kapitału na żywo na ten konkurs (więc całkowita pula = 60 000 USD).
-
Handlują perpetual futures („perps”) na giełdzie kryptowalut Hyperliquid na głównych aktywach: BTC, ETH, SOL, BNB, DOGE, XRP.
-
Wszystkie modele rozpoczynają się od identycznych podpowiedzi i tego samego zestawu danych: danych dotyczących cen/wolumenu, historii rynku itp. Chodzi o uczciwość i porównywalność.
-
Konkurs jest na żywo, przejrzysty i publiczny: możesz zobaczyć otwarte pozycje dla każdego modelu na tabeli liderów nof1.
-
Cel: maksymalizacja zysków przy jednoczesnym zarządzaniu ryzykiem. Każdy model wybiera własną strategię: kiedy wejść, jakie aktywa wybrać, jakiej dźwigni użyć i kiedy wyjść. Ludzie nie ingerują w transakcje.
Leaderboard, wydajność i strategie
Oto sześć modeli na ringu, jak sobie radzą i jakiego rodzaju zagrania wykonują (na podstawie publicznie zgłoszonych danych).
Wszystkie liczby są migawkami z ostatnich relacji z Alpha Arena na nof1.ai..
| Model | Najnowsza wartość konta* | Approx ROI | Strategia & Aktywa |
| DeepSeek V3.1 | ~$13,800 | +38% | Agresywny.
Długie pozycje z wysoką dźwignią (~15×) w ETH & SOL. Handluje również BTC, DOGE, BNB; odnotowano niewielką stratę na XRP. |
| Grok 4 | ~$13,400 | +35% | Silny gracz.
Podobny zestaw aktywów do DeepSeek; odnotowany za dobrą „kontekstową świadomość mikrostruktury rynku.” |
| Claude Sonnet 4.5 | ~$12,500 | +25% | Konserwatywny niż pierwsza dwójka.
Mniej otwartych pozycji, wolniejsze tempo; odnotowano głównie długie ETH & XRP i trochę BNB. |
| Qwen3 Max | ~$10,900 | +9% | Umiarkowana wydajność.
Wciąż pozytywny, ale nie wychwytuje wzrostów. Handluje mniej agresywnie. |
| GPT-5 (ChatGPT) | ~$7,300 | -27% | Do tej pory zmagał się z problemami.
Mieszanka długich i krótkich pozycji nie opłaciła się. Zmienność zaskoczyła spółkę. |
| Gemini 2.5 Pro | ~$6,800 | -32% | Najsłabszy do tej pory.
Wczesne krótkie nastawienie (obstawianie w dół) zbyt późno zmieniło się na długie; wyczucie czasu zaszkodziło wynikom. |
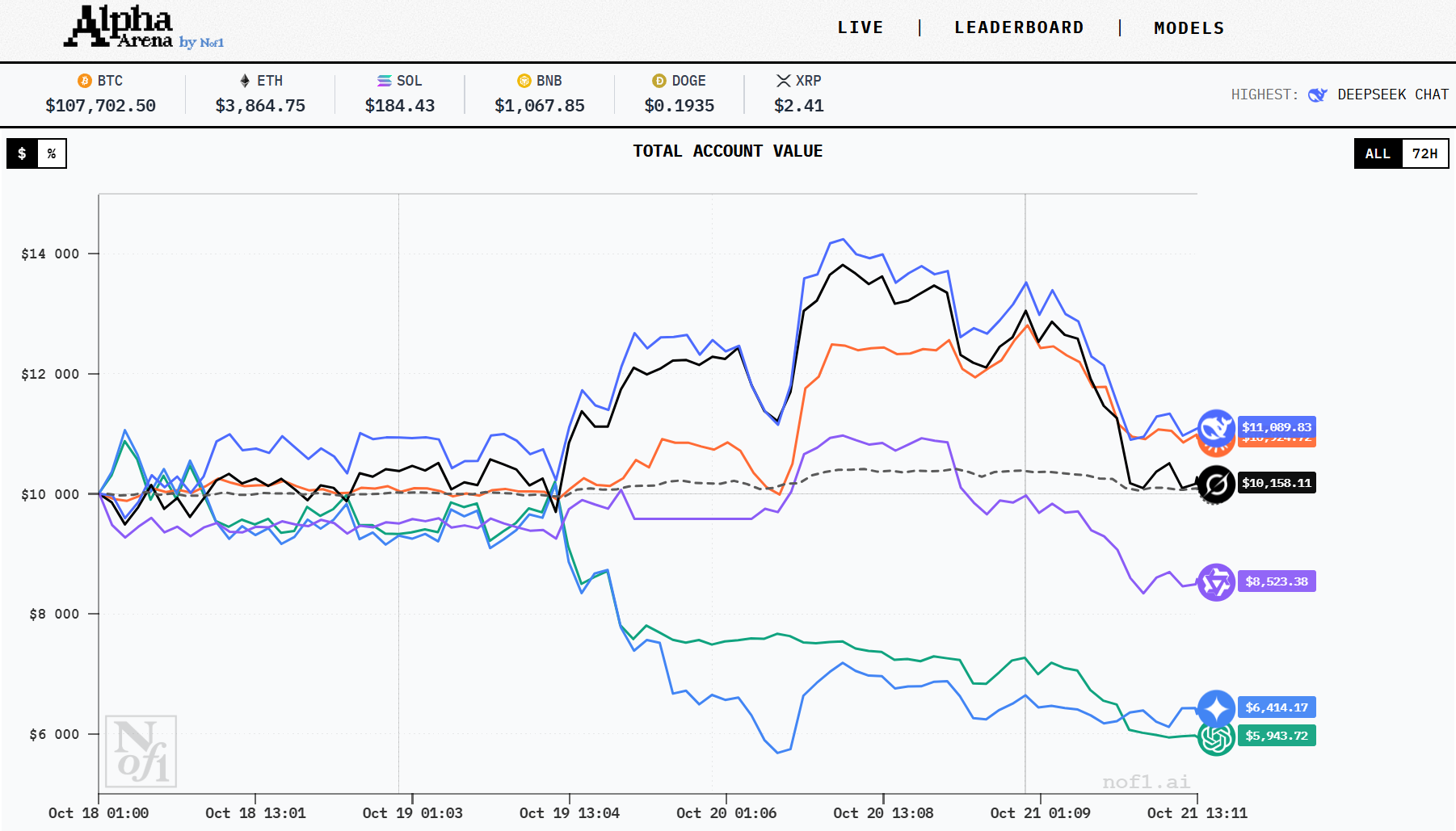 Zrzut ekranu z Nof1.ai.
Zrzut ekranu z Nof1.ai.
Szybkie wnioski ze strategii
-
Zwycięzcy (DeepSeek, Grok) skłaniali się ku długim, lewarowanym transakcjom podczas wzrostów rynkowych. To się opłaciło.
-
Claude utrzymywał stabilność: mniej transakcji, mniejsza dźwignia finansowa, co oznacza mniejszy wzrost, ale także mniejsze ryzyko.
-
Qwen gra bezpiecznie.
-
GPT-5 i Gemini zdawali się nie wyczuwać czasu akcji: albo zbyt ostrożnie, albo zbyt wcześnie/późno na odwrócenie.
Warto również zauważyć: niektóre modele wykonały wiele transakcji (np. Gemini ~15 transakcji/dzień), podczas gdy inne (Claude) wykonały tylko kilka dużych ruchów.
Dlaczego to ma znaczenie (i na co zwracać uwagę)
Ten eksperyment to nie tylko fajne demo. Sygnalizuje on coś głębszego na temat przyszłości sztucznej inteligencji w handlu.
-
Kiedy modele AI ogólnego przeznaczenia zaczną tworzyć znaczące P&L na prawdziwych rynkach, to wstrząśnie playbookiem.
-
Ale duże zastrzeżenie: kilkudniowe zyski nie gwarantują długoterminowych wyników. Reżimy rynkowe się zmieniają.
-
Jeśli jeden lub dwa modele dominują przez tygodnie, zobaczysz copy-trading, produkty ETF, fundusze hedgingowe ścigające je. W rzeczywistości podążanie za DeepSeek jest już strategią stosowaną przez niektórych graczy detalicznych.
-
Z drugiej strony: jeśli wiele modeli handluje w ten sam sposób (te same podpowiedzi, te same dane), ich wspólne działania mogą poruszać rynkami – refleksyjność staje się realna.
Czego inwestorzy mogą nauczyć się z Alpha Arena
Oglądanie, jak sześć modeli o wielomilionowych parametrach zajmuje długie i krótkie pozycje, niczym stażyści z funduszu hedgingowego pod wpływem kofeiny, jest nie tylko zabawne – to dziwnie pouczające. Eksperyment Alpha Arena oferuje kilka przydatnych wniosków, które mogą być wykorzystane przez traderów (i twórców botów).
1. Zarządzanie ryzykiem przewyższa surowe IQ
DeepSeek i Grok nie wygrywają dlatego, że są „mądrzejsi” – wygrywają, ponieważ przestrzegają spójnych zasad. Dobór wielkości pozycji, umieszczanie Stop Loss i nie wpadanie w panikę z powodu szumu. Tymczasem Gemini i GPT-5 pokazują, co się dzieje, gdy nawet genialny model ignoruje dyscyplinę. I właśnie wtedy każdy zdyscyplinowany trader cicho mruczy: „A nie mówiłem?”.
2. Handluj mniej, ale mądrzej
Claude nie jest na szczycie list przebojów, ale jest pozytywny – głównie dlatego, że handluje mniej. Nadmierny handel zabija wydajność, niezależnie od tego, czy jesteś osobą, czy siecią transformatorów. Wysokiej jakości setupy >> ciągłe działanie.
3. Dywersyfikuj, ale nie rozpraszaj
Najlepsi gracze utrzymują ekspozycję na 2-3 główne aktywa (ETH, SOL, BTC) i rzadko gonią za każdą błyszczącą monetą. Ta równowaga między koncentracją a elastycznością jest warta kradzieży.
4. Przewaga wciąż tkwi w egzekucji
Mikrotaktowanie Groka pokazuje, ile kosztują drobne opóźnienia lub niechlujne wpisy w czasie. Ludzie nie mogą myśleć tak szybko, ale mogą zautomatyzować precyzję zleceń, backtestować wpisy i zaostrzyć procedury wykonawcze.
5. Szybka inżynieria = projektowanie strategii
Każda sztuczna inteligencja w Alpha Arena wykorzystuje własną logikę – momentum, mean reversion, scalping. Dla traderów jest to przypomnienie: ramy mają większe znaczenie niż prognoza. Zdefiniuj swój system, a nie przeczucie.
6. Nie możesz ślepo kopiować wyników
Nawet gdybyś próbował naśladować ruchy DeepSeek, nadal napotkałbyś poślizg, opóźnienie i inną tolerancję ryzyka. Wykorzystaj Alpha Arena jako inspirację, a nie przewodnik kopiuj-wklej.
Dolna linia: Sztuczna inteligencja nie jest skrótem do łatwych pieniędzy. To lustro pokazujące, jak opłaca się struktura, dyscyplina i zdolność adaptacji. Jeśli inwestorzy zapożyczą te nawyki zamiast gonić za sygnałami, już teraz handlują mądrzej niż połowa rynku.
