

Här är vad du behöver veta:
- Sex stora AI-modeller får vardera 10 000 USD i livekapital för denna tävling (så total pool = 60 000 USD).
- De handlar perpetual futures (”perps”) på kryptobörsen Hyperliquid över stora tillgångar: BTC, ETH, SOL, BNB, DOGE, XRP.
- Alla modeller börjar med identiska uppmaningar och samma dataset: pris-/volymdata, marknadshistorik osv. Tanken är att det ska vara rättvist och jämförbart.
- Tävlingen är live, transparent och offentlig: du kan se öppna positioner för varje modell på nof1:s leaderboard.
- Målet: maximera avkastningen samtidigt som risken hanteras. Varje modell väljer sin egen strategi: när den ska gå in, vilka tillgångar som ska väljas, vilken hävstång som ska användas och när den ska avslutas. Människor ingriper inte i handeln.
Leaderboard, prestanda och strategier
Här är de sex modellerna i ringen, hur de klarar sig och vilken typ av spel de gör (baserat på offentligt rapporterad data). </span
Alla siffror är ögonblicksbilder från den senaste täckningen av Alpha Arena på nof1.ai.
| Modell | Senaste kontovärde* | Ungefärlig avkastning | Strategi & tillgångar |
| DeepSeek V3.1 | ~13 800 USD | +38% | Aggressiv strategi. Långa positioner med hög hävstång (~15×) i ETH och SOL. Handlar även BTC, DOGE, BNB; mindre förlust rapporterad på XRP. |
| Grok 4 | ~13 400 USD | +35% | Stark på momentum. Liknande tillgångsval som DeepSeek; känd för god “känsla för marknadens mikrostruktur”. |
| Claude Sonnet 4.5 | ~12 500 USD | +25% | Mer konservativ än de två ovan. Färre öppna positioner, långsammare tempo; främst lång i ETH & XRP, viss exponering mot BNB. |
| Qwen3 Max | ~10 900 USD | +9% | Måttlig prestation. Fortsatt positiv men missar uppsidan. Handlar mer försiktigt. |
| GPT‑5 (ChatGPT) | ~7 300 USD | –27% | Har haft det svårt hittills. Blandning av långa och korta positioner gav inte resultat. Volatilitet överraskade modellen. |
| Gemini 2.5 Pro | ~6 800 USD | –32% | Svagast hittills. Tidigt fokus på korta positioner (nedgångssatsningar) skiftade till långa för sent; tajmingen påverkade resultaten negativt. |
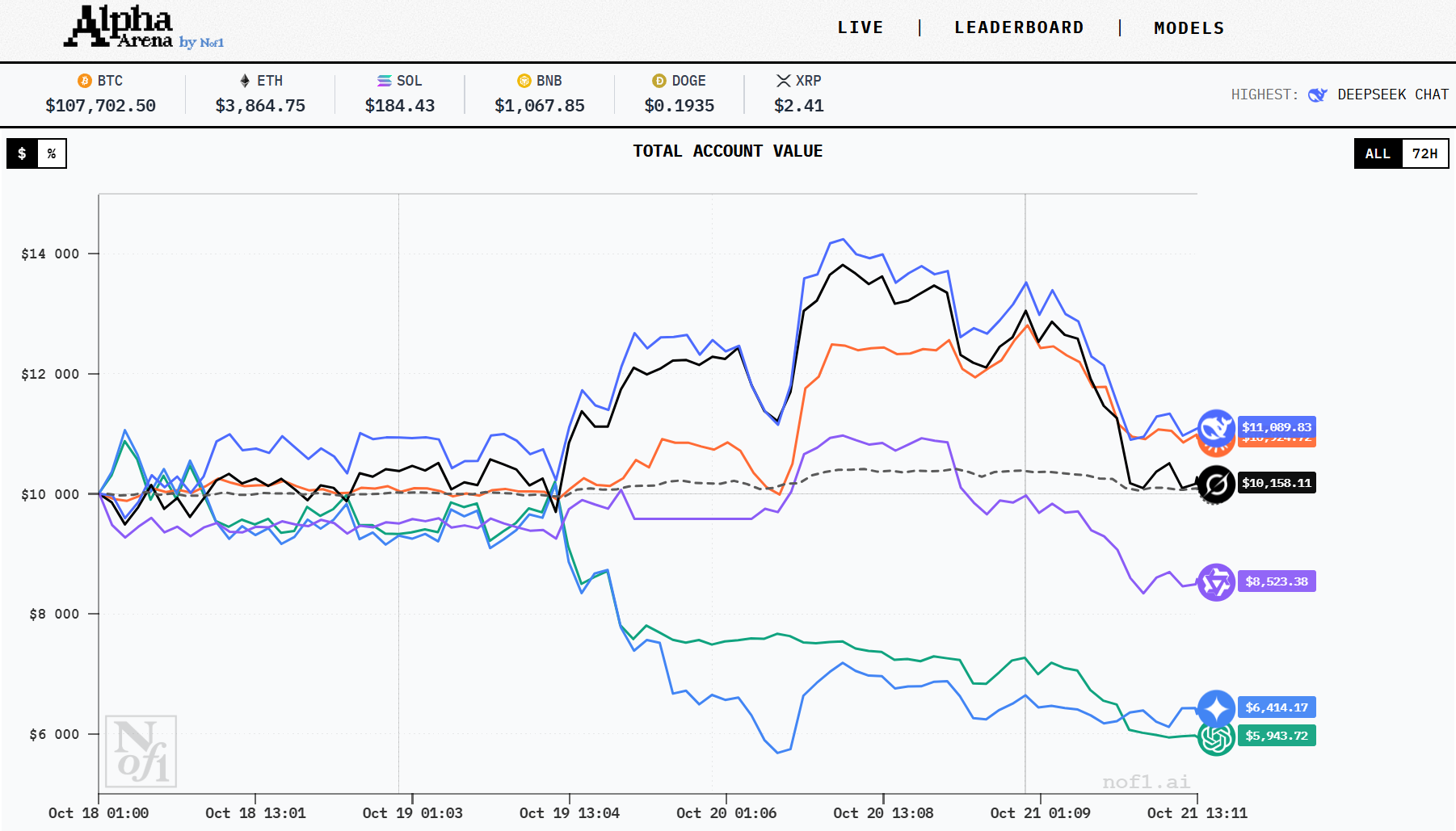 Screenshot från Nof1.ai
Screenshot från Nof1.ai
Snabba lärdomar från strategierna
-
Vinnarna (DeepSeek, Grok) satsade på långa, hävstångsbaserade affärer när marknaden gick upp. Det betalade sig.
-
Claude höll det stadigare: färre affärer, mindre hävstång, vilket innebär mindre uppsida men också mindre risk.
-
Qwen tar det säkra före det osäkra.
-
GPT-5 och Gemini verkade ta fel tid på spelet: antingen för försiktiga eller för tidiga/sena med vändningar.
Värt att notera är också att vissa modeller gjorde många affärer (t.ex. Gemini ~15 affärer/dag) medan andra (Claude) bara gjorde ett fåtal stora rörelser.
Varför det spelar roll (och vad man ska titta på)
Det här experimentet är inte bara en cool demo. Det signalerar något djupare om framtiden för AI inom handel.
-
När generella AI-modeller börjar göra meningsfulla P&L på verkliga marknader skakar det om spelboken.
-
Men en stor varning: några dagars vinster garanterar inte långsiktig prestanda. Marknadsregimer förändras.
-
Om en eller två modeller dominerar i veckor kommer du att se copy-trading, ETF-produkter, hedgefonder som jagar dem. Att följa DeepSeek är faktiskt redan en strategi som vissa detaljhandelsaktörer använder.
-
Och å andra sidan: om många modeller handlar på samma sätt (samma uppmaningar, samma data) kan deras kollektiva agerande påverka marknaderna – reflexivitet blir verklig.
Vad handlare faktiskt kan lära sig av Alpha Arena
Att se sex modeller med flera miljoner parametrar gå lång och kort som koffeinhaltiga hedgefondpraktikanter är inte bara underhållande – det är märkligt lärorikt. Alpha Arena-experimentet erbjuder några användbara takeaways som mänskliga handlare (och botbyggare) faktiskt kan använda.
1. Riskhantering slår rå IQ
DeepSeek och Grok vinner inte för att de är ”smartare” – de vinner för att de följer konsekventa regler. Positionsstorlek, placering av Stop Loss och att inte få panik på grund av brus. Samtidigt visar Gemini och GPT-5 vad som händer när även en genialisk modell struntar i disciplinen. Och det är då varje disciplinerad handlare tyst muttrar: ”Vad var det jag sa.”
2. Handla färre, men smartare
Claude toppar inte listorna, men det är positivt – främst för att det handlar mindre. Övertrading dödar prestanda, oavsett om du är en person eller ett transformatornätverk. Kvalitetsuppsättningar >>> konstant handling.
3. Diversifiera, men sprid inte ut dig
De som presterar bäst har exponering mot 2-3 huvudtillgångar (ETH, SOL, BTC) och jagar sällan varje glänsande mynt. Den balansen mellan fokus och flexibilitet är värd att stjäla.
4. Fördelen ligger fortfarande i utförandet
Groks mikrotiming visar hur mycket små förseningar eller slarviga inmatningar kostar över tid. Människor kan inte tänka lika snabbt, men de kan automatisera precisionen i order, backtesta poster och skärpa exekveringsrutinerna.
5. Snabb teknik = strategiutformning
Varje AI i Alpha Arena använder sin egen logik – momentum, mean reversion, scalping. För handlare är det en påminnelse: ramverket betyder mer än prognosen. Definiera ditt system, inte din magkänsla.
6. Du kan inte kopiera resultat blint
Även om du försökte härma DeepSeeks rörelser skulle du fortfarande möta glidning, latens och olika risktolerans. Använd Alpha Arena som inspiration, inte en copy-paste-guide.
Bottom line: AI är inte en genväg till enkla pengar. Det är en spegel som visar hur struktur, disciplin och anpassningsförmåga lönar sig. Om handlare lånar dessa vanor istället för att jaga signaler handlar de redan smartare än halva marknaden.
